publications
My publications in reversed chronological order.
2026
-
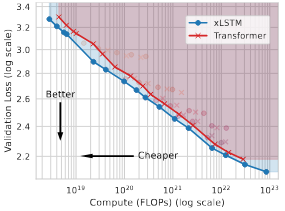 xLSTM Scaling Laws: Competitive Performance with Linear Time-ComplexityMaximilian Beck, Kajetan Schweighofer , Sebastian Böck , and 2 more authorsIn International Conference on Learning Representations (ICLR) , 2026
xLSTM Scaling Laws: Competitive Performance with Linear Time-ComplexityMaximilian Beck, Kajetan Schweighofer , Sebastian Böck , and 2 more authorsIn International Conference on Learning Representations (ICLR) , 2026Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM’s advantage widens as training and inference contexts grow.
@inproceedings{beck2025xlstmscalinglaws, title = {xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity}, author = {Beck, Maximilian and Schweighofer, Kajetan and Böck, Sebastian and Lehner, Sebastian and Hochreiter, Sepp}, booktitle = {International Conference on Learning Representations (ICLR)}, url = {https://arxiv.org/abs/2510.02228}, year = {2026}, } -
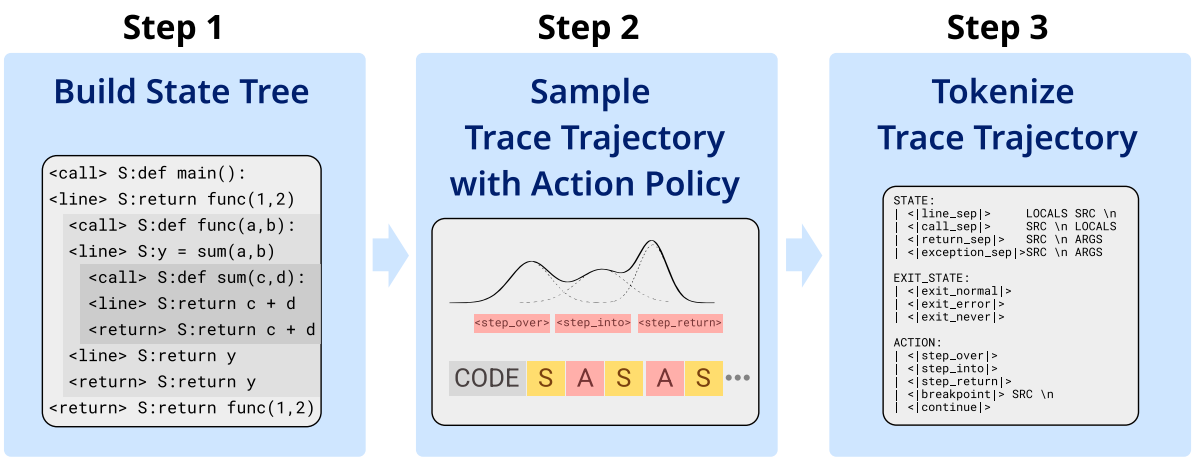 Towards a Neural Debugger for PythonMaximilian Beck, Jonas Gehring , Jannik Kossen , and 1 more authorIn Arxiv , 2026
Towards a Neural Debugger for PythonMaximilian Beck, Jonas Gehring , Jannik Kossen , and 1 more authorIn Arxiv , 2026Training large language models (LLMs) on Python execution traces grounds them in code execution and enables the line-by-line execution prediction of whole Python programs, effectively turning them into neural interpreters (FAIR CodeGen Team et al., 2025). However, developers rarely execute programs step by step; instead, they use debuggers to stop execution at certain breakpoints and step through relevant portions only while inspecting or modifying program variables. Existing neural interpreter approaches lack such interactive control. To address this limitation, we introduce neural debuggers: language models that emulate traditional debuggers, supporting operations such as stepping into, over, or out of functions, as well as setting breakpoints at specific source lines. We show that neural debuggers – obtained via fine-tuning large LLMs or pre-training smaller models from scratch – can reliably model both forward execution (predicting future states and outputs) and inverse execution (inferring prior states or inputs) conditioned on debugger actions. Evaluated on CruxEval, our models achieve strong performance on both output and input prediction tasks, demonstrating robust conditional execution modeling. Our work takes first steps towards future agentic coding systems in which neural debuggers serve as a world model for simulated debugging environments, providing execution feedback or enabling agents to interact with real debugging tools. This capability lays the foundation for more powerful code generation, program understanding, and automated debugging.
@inproceedings{beck2026neural_debugger, title = {Towards a Neural Debugger for Python}, author = {Beck, Maximilian and Gehring, Jonas and Kossen, Jannik and Synnaeve, Gabriel}, booktitle = {Arxiv}, url = {https://arxiv.org/abs/2603.09951}, year = {2026}, } - ICLR26Short window attention enables long-term memorizationLoïc Cabannes , Maximilian Beck, Gergely Szilvasy , and 6 more authorsIn International Conference on Learning Representations (ICLR) , 2026
Recent works show that hybrid architectures combining sliding window softmax attention layers with linear recurrent neural network (RNN) layers outperform both of these architectures taken separately. However, the impact of the window length and the interplay between softmax attention and linear RNN layers remain under-studied. In this work, we introduce SWAX, a hybrid architecture consisting of sliding-window attention and xLSTM linear RNN layers. A counter-intuitive finding with SWAX is that larger sliding windows do not improve the long-context performance. In fact, short window attention encourages the model to better train the long-term memory of the xLSTM, by relying less on the softmax attention mechanism for long context-retrieval. The issue with small sliding windows is that they are detrimental for short-context tasks, which could be solved with information from moderately larger sliding windows otherwise. Therefore, we train SWAX by stochastically changing the sliding window size, forcing the model to leverage both a longer context window and the xLSTM memory. SWAX trained with stochastic window sizes significantly outperforms regular window attention both on short and long-context problems.
@inproceedings{cabannes2025swax, title = {Short window attention enables long-term memorization}, author = {Cabannes, Loïc and Beck, Maximilian and Szilvasy, Gergely and Douze, Matthijs and Lomeli, Maria and Copet, Jade and Mazaré, Pierre-Emmanuel and Synnaeve, Gabriel and Jégou, Hervé}, booktitle = {International Conference on Learning Representations (ICLR)}, url = {https://arxiv.org/abs/2509.24552}, year = {2026}, }

2025
-
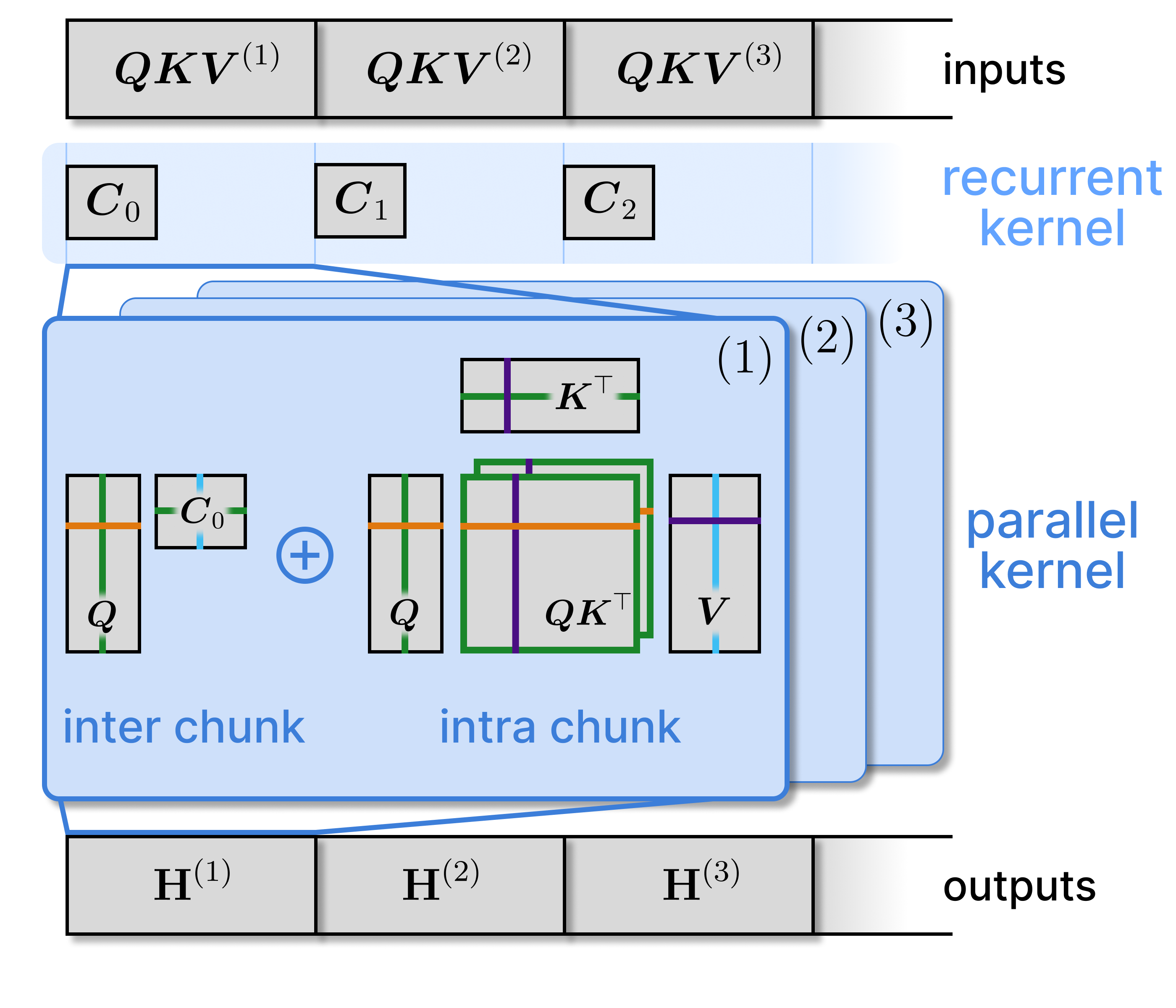 Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM KernelsMaximilian Beck, Korbinian Pöppel , Phillip Lippe , and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS) , 2025
Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM KernelsMaximilian Beck, Korbinian Pöppel , Phillip Lippe , and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS) , 2025Linear RNNs with gating recently demonstrated competitive performance compared to Transformers in language modeling. Although their linear compute scaling in sequence length offers theoretical runtime advantages over Transformers, realizing these benefits in practice requires optimized custom kernels, as Transformers rely on the highly efficient Flash Attention kernels (Dao, 2024). Leveraging the chunkwise-parallel formulation of linear RNNs, Flash Linear Attention (FLA) (Yang & Zhang, 2024) shows that linear RNN kernels are faster than Flash Attention, by parallelizing over chunks of the input sequence. However, since the chunk size of FLA is limited, many intermediate states must be materialized in GPU memory. This leads to low arithmetic intensity and causes high memory consumption and IO cost, especially for long-context pre-training. In this work, we present Tiled Flash Linear Attention (TFLA), a novel kernel algorithm for linear RNNs, that enables arbitrary large chunk sizes and high arithmetic intensity by introducing an additional level of sequence parallelization within each chunk. First, we apply TFLA to the xLSTM with matrix memory, the mLSTM (Beck et al., 2024). Second, we propose an mLSTM variant with sigmoid input gate and reduced computation for even faster kernel runtimes at equal language modeling performance. In our speed benchmarks, we show that our new mLSTM kernels based on TFLA outperform highly optimized Flash Attention, Linear Attention and Mamba kernels, setting a new state of the art for efficient long-context sequence modeling primitives.
@inproceedings{beck2025tfla, title = {Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels}, author = {Beck, Maximilian and P{\"o}ppel, Korbinian and Lippe, Phillip and Hochreiter, Sepp}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, url = {https://arxiv.org/abs/2503.14376}, year = {2025}, } - ICML25xLSTM 7B: A Recurrent LLM for Fast and Efficient InferenceMaximilian Beck*, Korbinian Pöppel* , Phillip Lippe* , and 5 more authorsIn International Conference on Machine Learning (ICML) , 2025
Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM- based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM’s architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM’s potential as a founda tional architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source. Model: https://huggingface.co/NX-AI/xLSTM-7b Code: https://github.com/NX-AI/xlstm and https://github.com/NX-AI/xlstm-jax.
@inproceedings{beck2025xlstm7b, title = {xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference}, author = {Beck*, Maximilian and P{\"o}ppel*, Korbinian and Lippe*, Phillip and Kurle, Richard and Blies, Patrick M. and Klambauer, G{\"u}nter and B{\"o}ck, Sebastian and Hochreiter, Sepp}, booktitle = {International Conference on Machine Learning (ICML)}, url = {https://arxiv.org/abs/2503.13427}, year = {2025}, } -
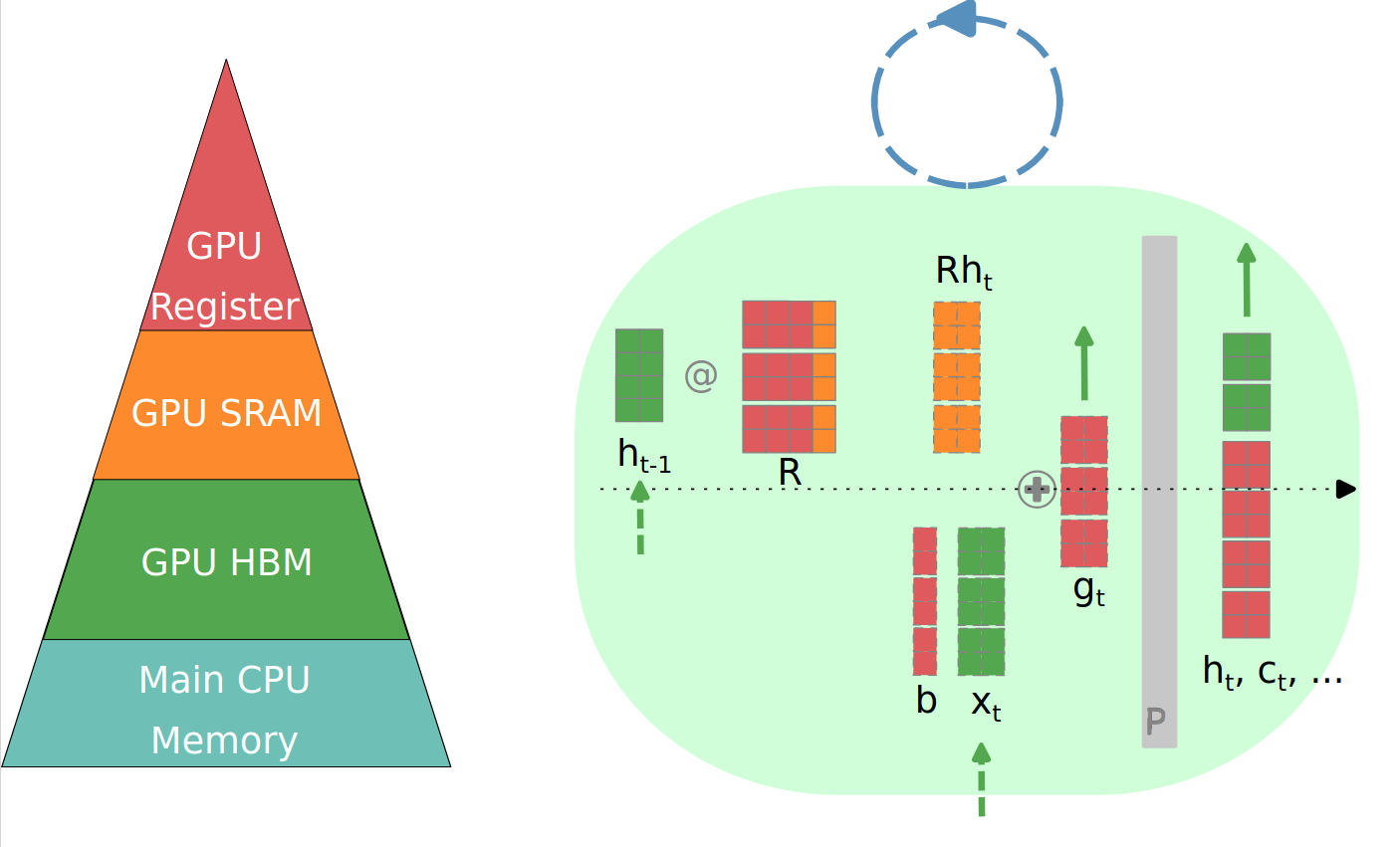 FlashRNN: I/O-Aware Optimization of Traditional RNNs on modern hardwareKorbinian Pöppel , Maximilian Beck, and Sepp HochreiterIn International Conference on Learning Representations (ICLR) , 2025
FlashRNN: I/O-Aware Optimization of Traditional RNNs on modern hardwareKorbinian Pöppel , Maximilian Beck, and Sepp HochreiterIn International Conference on Learning Representations (ICLR) , 2025While Transformers and other sequence-parallelizable neural network architectures seem like the current state of the art in sequence modeling, they specifically lack state-tracking capabilities. These are important for time-series tasks and logical reasoning. Traditional RNNs like LSTMs and GRUs, as well as modern variants like sLSTM do have these capabilities at the cost of strictly sequential processing. While this is often seen as a strong limitation, we show how fast these networks can get with our hardware-optimization FlashRNN in Triton and CUDA, optimizing kernels to the register level on modern GPUs. We extend traditional RNNs with a parallelization variant that processes multiple RNNs of smaller hidden state in parallel, similar to the head-wise processing in Transformers. To enable flexibility on different GPU variants, we introduce a new optimization framework for hardware-internal cache sizes, memory and compute handling. It models the hardware in a setting using polyhedral-like constraints, including the notion of divisibility. This speeds up the solution process in our ConstrINT library for general integer constraint satisfaction problems (integer CSPs). We show that our kernels can achieve 50x speed-ups over a vanilla PyTorch implementation and allow 40x larger hidden sizes compared to our Triton implementation. We will open-source our kernels and the optimization library to boost research in the direction of state-tracking enabled RNNs and sequence modeling.
@inproceedings{poeppel2025flashrnn, title = {Flash{RNN}: I/O-Aware Optimization of Traditional {RNN}s on modern hardware}, author = {P{\"o}ppel, Korbinian and Beck, Maximilian and Hochreiter, Sepp}, booktitle = {International Conference on Learning Representations (ICLR)}, url = {https://openreview.net/forum?id=l0ZzTvPfTw}, year = {2025}, } - ICML25A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics TasksThomas Schmied , Thomas Adler , Vihang Patil , and 6 more authorsIn International Conference on Machine Learning (ICML) , 2025
In recent years, there has been a trend in the field of Reinforcement Learning (RL) towards large action models trained offline on large-scale datasets via sequence modeling. Existing models are primarily based on the Transformer architecture, which result in powerful agents. However, due to slow inference times, Transformer-based approaches are impractical for real-time applications, such as robotics. Recently, modern recurrent architectures, such as xLSTM and Mamba, have been proposed that exhibit parallelization benefits during training similar to the Transformer architecture while offering fast inference. In this work, we study the aptitude of these modern recurrent architectures for large action models. Consequently, we propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed.
@inproceedings{schmied2024lram, title = {A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks}, author = {Schmied, Thomas and Adler, Thomas and Patil, Vihang and Beck, Maximilian and Pöppel, Korbinian and Brandstetter, Johannes and Klambauer, Günter and Pascanu, Razvan and Hochreiter, Sepp}, booktitle = {International Conference on Machine Learning (ICML)}, url = {https://arxiv.org/abs/2410.22391}, year = {2025}, } - ICLR25Vision-LSTM: xLSTM as Generic Vision BackboneBenedikt Alkin , Maximilian Beck, Korbinian Pöppel , and 2 more authorsIn International Conference on Learning Representations (ICLR) , 2025
Transformers are widely used as generic backbones in computer vision, despite initially introduced for natural language processing. Recently, the Long Short-Term Memory (LSTM) has been extended to a scalable and performant architecture - the xLSTM - which overcomes long-standing LSTM limitations via exponential gating and parallelizable matrix memory structure. In this report, we introduce Vision-LSTM (ViL), an adaption of the xLSTM building blocks to computer vision. ViL comprises a stack of xLSTM blocks where odd blocks process the sequence of patch tokens from top to bottom while even blocks go from bottom to top. Experiments show that ViL holds promise to be further deployed as new generic backbone for computer vision architectures.
@inproceedings{alkin2024visionlstm, title = {Vision-LSTM: xLSTM as Generic Vision Backbone}, author = {Alkin, Benedikt and Beck, Maximilian and P{\"o}ppel, Korbinian and Hochreiter, Sepp and Brandstetter, Johannes}, booktitle = {International Conference on Learning Representations (ICLR)}, url = {https://nx-ai.github.io/vision-lstm/}, year = {2025}, }

2024
-
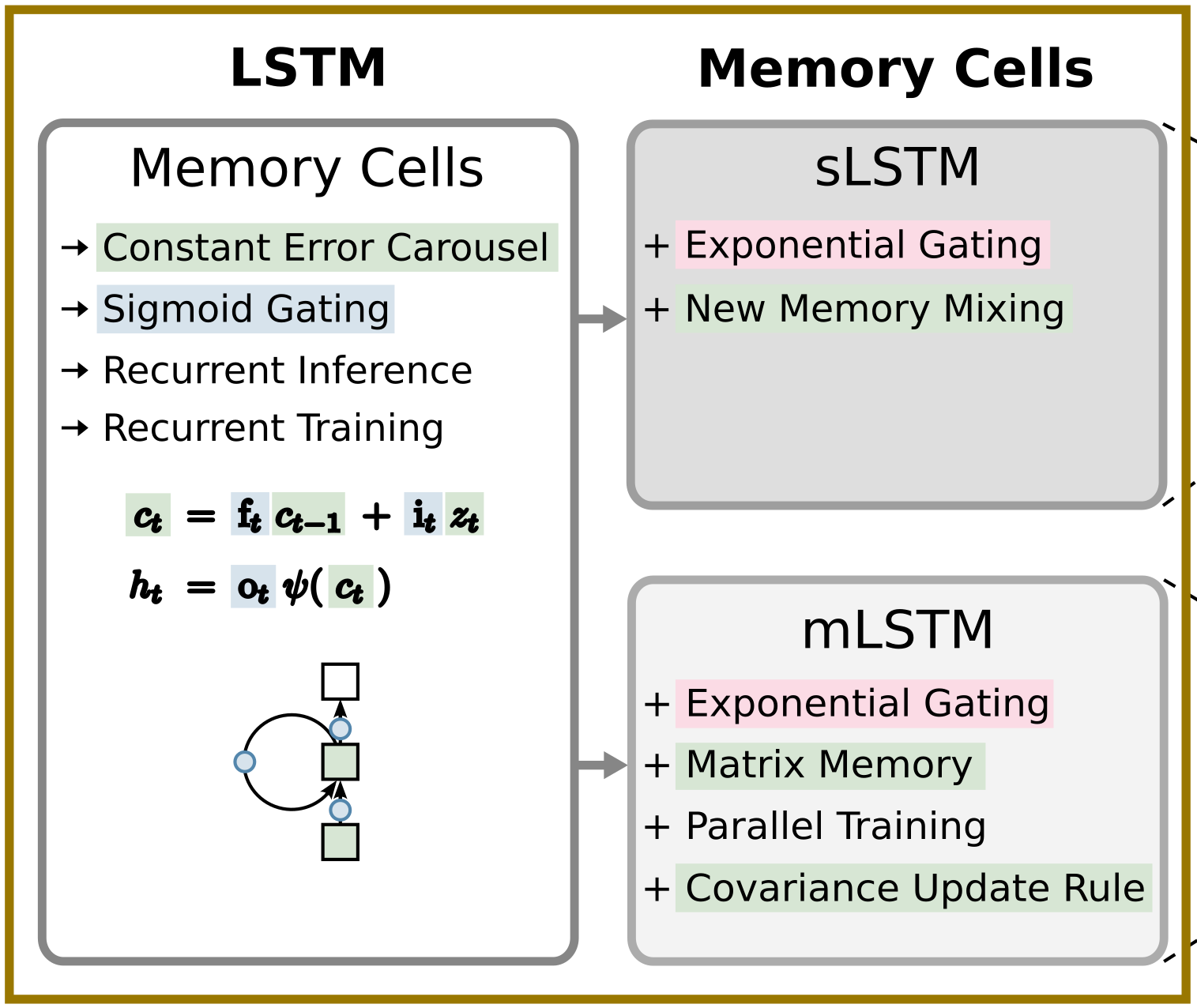 xLSTM: Extended Long Short-Term MemoryMaximilian Beck*, Korbinian Pöppel* , Markus Spanring , and 6 more authorsIn Advances in Neural Information Processing Systems (NeurIPS) , 2024
xLSTM: Extended Long Short-Term MemoryMaximilian Beck*, Korbinian Pöppel* , Markus Spanring , and 6 more authorsIn Advances in Neural Information Processing Systems (NeurIPS) , 2024In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
@inproceedings{beck2024xlstm, title = {xLSTM: Extended Long Short-Term Memory}, author = {Beck*, Maximilian and P{\"o}ppel*, Korbinian and Spanring, Markus and Auer, Andreas and Prudnikova, Oleksandra and Kopp, Michael and Klambauer, G{\"u}nter and Brandstetter, Johannes and Hochreiter, Sepp}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, url = {https://arxiv.org/abs/2405.04517}, year = {2024}, }

2023
- Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by AggregationMarius-Constantin Dinu , Markus Holzleitner , Maximilian Beck, and 7 more authorsIn International Conference on Learning Representations (ICLR) , 2023
We study the problem of choosing algorithm hyper-parameters in unsupervised domain adaptation, i.e., with labeled data in a source domain and unlabeled data in a target domain, drawn from a different input distribution. We follow the strategy to compute several models using different hyper-parameters, and, to subsequently compute a linear aggregation of the models. While several heuristics exist that follow this strategy, methods are still missing that rely on thorough theories for bounding the target error. In this turn, we propose a method that extends weighted least squares to vector-valued functions, e.g., deep neural networks. We show that the target error of the proposed algorithm is asymptotically not worse than twice the error of the unknown optimal aggregation. We also perform a large scale empirical comparative study on several datasets, including text, images, electroencephalogram, body sensor signals and signals from mobile phones. Our method outperforms deep embedded validation (DEV) and importance weighted validation (IWV) on all datasets, setting a new state-of-the-art performance for solving parameter choice issues in unsupervised domain adaptation with theoretical error guarantees. We further study several competitive heuristics, all outperforming IWV and DEV on at least five datasets. However, our method outperforms each heuristic on at least five of seven datasets.
@inproceedings{dinu2023aggregationmethod, title = {Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation}, author = {Dinu, Marius-Constantin and Holzleitner, Markus and Beck, Maximilian and Nguyen, Hoan Duc and Huber, Andrea and Eghbal-zadeh, Hamid and Moser, Bernhard A. and Pereverzyev, Sergei and Hochreiter, Sepp and Zellinger, Werner}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2023}, url = {https://openreview.net/forum?id=M95oDwJXayG}, }
2022
-
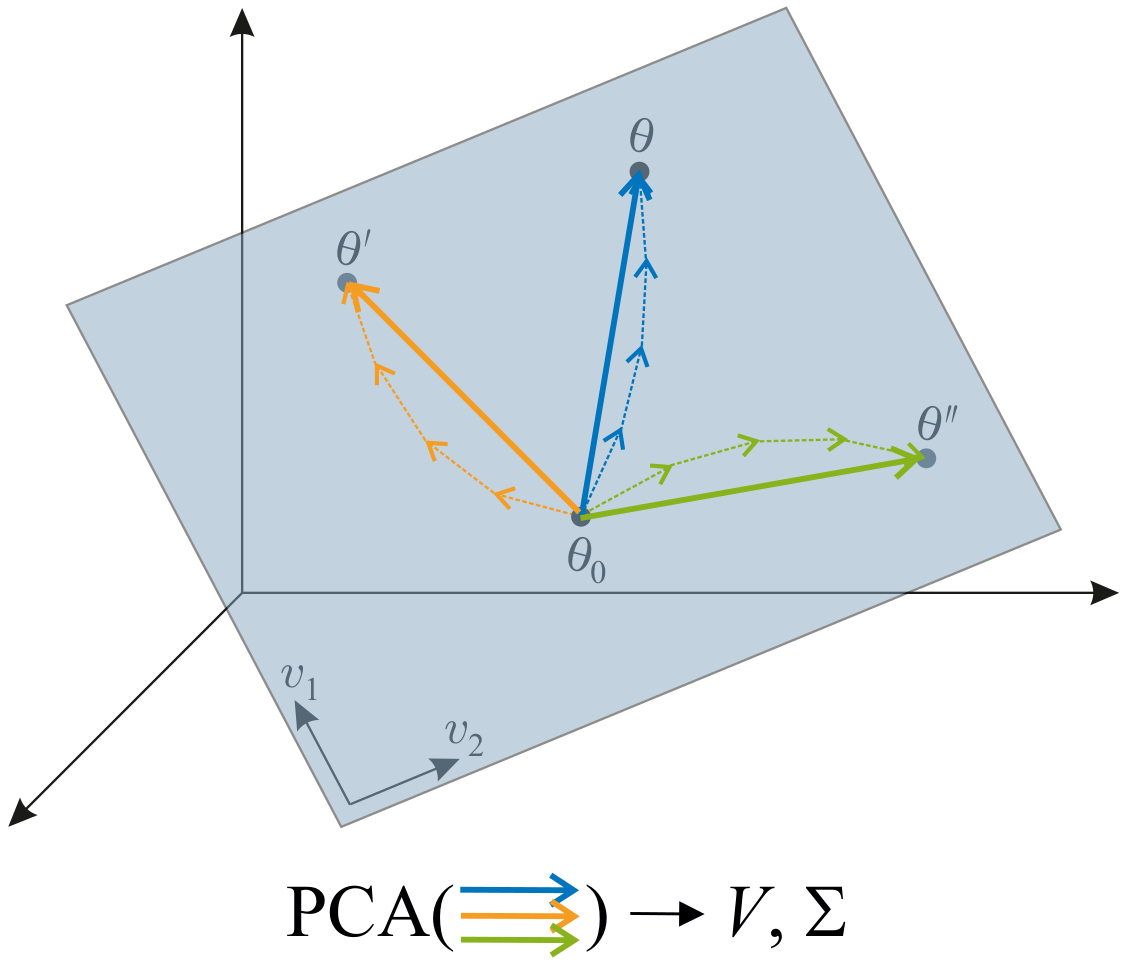 Few-Shot Learning by Dimensionality Reduction in Gradient SpaceMartin Gauch , Maximilian Beck, Thomas Adler , and 10 more authorsIn The Conference on Lifelong Learning Agents (CoLLAs) , 2022
Few-Shot Learning by Dimensionality Reduction in Gradient SpaceMartin Gauch , Maximilian Beck, Thomas Adler , and 10 more authorsIn The Conference on Lifelong Learning Agents (CoLLAs) , 2022We introduce SubGD, a novel few-shot learning method which is based on the recent finding that stochastic gradient descent updates tend to live in a low-dimensional parameter subspace. In experimental and theoretical analyses, we show that models confined to a suitable predefined subspace generalize well for few-shot learning. A suitable subspace fulfills three criteria across the given tasks: it (a) allows to reduce the training error by gradient flow, (b) leads to models that generalize well, and (c) can be identified by stochastic gradient descent. SubGD identifies these subspaces from an eigendecomposition of the auto-correlation matrix of update directions across different tasks. Demonstrably, we can identify low-dimensional suitable subspaces for few-shot learning of dynamical systems, which have varying properties described by one or few parameters of the analytical system description. Such systems are ubiquitous among real-world applications in science and engineering. We experimentally corroborate the advantages of SubGD on three distinct dynamical systems problem settings, significantly outperforming popular few-shot learning methods both in terms of sample efficiency and performance.
@inproceedings{gauch2022subgd, title = {Few-Shot Learning by Dimensionality Reduction in Gradient Space}, author = {Gauch, Martin and Beck, Maximilian and Adler, Thomas and Kotsur, Dmytro and Fiel, Stefan and Eghbal-zadeh, Hamid and Brandstetter, Johannes and Kofler, Johannes and Holzleitner, Markus and Zellinger, Werner and Klotz, Daniel and Hochreiter, Sepp and Lehner, Sebastian}, booktitle = {The Conference on Lifelong Learning Agents (CoLLAs)}, year = {2022}, editor = {Chandar, Sarath and Pascanu, Razvan and Precup, Doina}, url = {https://proceedings.mlr.press/v199/gauch22a.html}, }
